pvigier's blog
computer science, programming and other ideas
Entity-Component-System – Part 1
This week, I have started working on my game engine for my game Vagabond. I have worked on an implementation of the entity-component-system pattern.
In this article, I want to share with you my implementation which is freely available on GitHub. But instead of just commenting the code, I want to explain how I designed it. Thus, I will start with the first implementation I coded, analyze its strengths and weaknesses and then show how I improved it. Finally, I will give a list of things that still could be improved.
Introduction
Motivation
I won’t go over all the benefits of ECS over the object oriented approach as many people have already done it very well. Historically, Scott Bilas was one of the first to speak about ECS at GDC 2002. Other famous introductions are Evolve Your Hierarchy by Mike West and the chapter Components in the awesome book Game Programming Patterns by Robert Nystrom.
To sum up briefly, the goal of ECS is to offer a data oriented approach to game entities and a nice separation between data and logic. Entities are made up of components which contain the data. And systems, which contain the logic, process the components.
In more technical details, ECS relies on composition instead of inheritance to build entities. Moreover, this data-oriented approach allows to be cache-friendly and consequently to achieve great performance.
Examples
Before diving in the code, I want to give you a glimpse of what we are going to build.
To define components, it is really easy:
struct Position : public Component<Position>
{
float x;
float y;
};
struct Velocity : public Component<Velocity>
{
float x;
float y;
};
As you can see, we will rely on the CRTP.
Then for technical reasons, that you will discover later, we have to fix the number of components and the number of systems:
constexpr auto ComponentCount = 32;
constexpr auto SystemCount = 8;
Now, we can define a system that will take all the entities that have both components and update their positions:
class PhysicsSystem : public System<ComponentCount, SystemCount>
{
public:
PhysicsSystem(EntityManager<ComponentCount, SystemCount>& entityManager) : mEntityManager(entityManager)
{
setRequirements<Position, Velocity>();
}
void update(float dt)
{
for (const auto& entity : getManagedEntities())
{
auto [position, velocity] = mEntityManager.getComponents<Position, Velocity>(entity);
position.x += velocity.x * dt;
position.y += velocity.y * dt;
}
}
private:
EntityManager<ComponentCount, SystemCount>& mEntityManager;
};
To declare the components by which it is interested, the system just uses the method setRequirements. Then in the update method, it can call the method getManagedEntities to iterate over all the entities that satisfy the requirements.
Finally, let us create an entity manager, register the components, create a system and some entities, and update the positions using the system:
auto manager = EntityManager<ComponentCount, SystemCount>();
manager.registerComponent<Position>();
manager.registerComponent<Velocity>();
auto system = manager.createSystem<PhysicsSystem>(manager);
for (auto i = 0; i < 10; ++i)
{
auto entity = manager.createEntity();
manager.addComponent<Position>(entity);
manager.addComponent<Velocity>(entity);
}
auto dt = 1.0f / 60.0f;
while (true)
system->update(dt);
Benchmarks
I do not pretend that we will make the best ECS library. I was just eager to try to build my own. In addition, I only worked on it for one week.
However, that is not a reason for creating something totally inefficient. Thus, I have set up some benchmarks:
- one that will create entities;
- another one that uses a system to iterate over the entities;
- the last one that creates and destroys entities;
All these benchmarks are parameterized with the number of entities, the number of components that each entity has, the maximum number of components and the maximum number of systems. Thus, we will be able to see how the implementation scale. In particular, I will show the results for three different profiles:
- A with 32 components and 16 systems;
- AA with 128 components and 32 systems;
- AAA with 512 components and 64 systems.
While these benchmarks give an idea of how well the implementation is, they are quite simple. For instance, in the benchmarks we only use homogeneous entities and the components are small.
Implementation
Entity
In my implementation, an entity is just an id, nothing more:
using Entity = uint32_t;
Moreover, in Entity.h, we will also define an alias Index that will be useful later:
using Index = uint32_t;
static constexpr auto InvalidIndex = std::numeric_limits<Index>::max();
I choose to use an uint32_t instead of a 64 bits type or std::size_t to save some space and improve cache friendliness. And we do not lose much as it is very unlikely that someone has billions of entities.
Component
Now let us define the base class for components:
template<typename T, auto Type>
class Component
{
public:
static constexpr auto type = static_cast<std::size_t>(Type);
};
The template class is really simple, it just stores a type id that will be used later to index some data structures by component type.
The first template parameter is the type of the component. The second one is a value convertible to std::size_t and will serve to set the component type id.
For instance, we can define a Position component like that:
struct Positon : Component<Position, 0>
{
float x;
float y;
};
However, it may be more convenient to use an enumeration:
enum class ComponentType
{
Position
};
struct Positon : Component<Position, ComponentType::Position>
{
float x;
float y;
};
In the introductory example, there was only one template parameter: we did not have to specify the type id manually. We will see later how to improve that and generate automatically the type ids.
EntityContainer
The EntityContainer class will be responsible for managing the entities and storing a std::bitset for each one. This bit set will represent the components that are owned by an entity.
As we will use entities to index containers and especially std::vectors we would like the ids to be as small as possible to allocate as little memory as possible. Consequently, we will recycle the id of an entity when it is destroyed. To do that, we will store the free ids in a container called mFreeEntities.
Here is the declaration of EntityContainer:
template<std::size_t ComponentCount, std::size_t SystemCount>
class EntityContainer
{
public:
void reserve(std::size_t size);
std::vector<std::bitset<ComponentCount>>& getEntityToBitset();
const std::bitset<ComponentCount>& getBitset(Entity entity) const;
Entity create();
void remove(Entity entity);
private:
std::vector<std::bitset<ComponentCount>> mEntityToBitset;
std::vector<Entity> mFreeEntities;
};
Let us take a look at the implementation of methods.
getEntityToBitset and getBitset are just two simple getters:
std::vector<std::bitset<ComponentCount>>& getEntityToBitset()
{
return mEntityToBitset;
}
const std::bitset<ComponentCount>& getBitset(Entity entity) const
{
return mEntityToBitset[entity];
}
The create method is more interesting:
Entity create()
{
auto entity = Entity();
if (mFreeEntities.empty())
{
entity = static_cast<Entity>(mEntityToBitset.size());
mEntityToBitset.emplace_back();
}
else
{
entity = mFreeEntities.back();
mFreeEntities.pop_back();
mEntityToBitset[entity].reset();
}
return entity;
}
If there is a free entity, it recycles it. Otherwise, it creates a new one.
The remove method just add the entity to remove in mFreeEntities:
void remove(Entity entity)
{
mFreeEntities.push_back(entity);
}
The last method is reserve, its purpose is to reserve memory for the different containers. As you may know, memory allocation is an expensive operation, so if you roughly know how many entities there will be in your game, reserving the memory can speed up things:
void reserve(std::size_t size)
{
mFreeEntities.resize(size);
std::iota(std::begin(mFreeEntities), std::end(mFreeEntities), 0);
mEntityToBitset.resize(size);
}
More than just reserving the memory, we also fill mFreeEntities.
ComponentContainer
The ComponentContainer class will be responsible for storing all the components of a given type.
In my architecture, all the components of a given type are stored contiguously. Thus, there is one big array for each component type, it is called mComponents.
Moreover, to be able to add, get or remove a component from an entity in constant time, we need to have a way to go from an entity to a component and from a component to an entity. To do that, we need two more data structures called mComponentToEntity and mEntityToComponent.
Here is the declaration of ComponentContainer:
template<typename T, std::size_t ComponentCount, std::size_t SystemCount>
class ComponentContainer : public BaseComponentContainer
{
public:
ComponentContainer(std::vector<std::bitset<ComponentCount>>& entityToBitset);
virtual void reserve(std::size_t size) override;
T& get(Entity entity);
const T& get(Entity entity) const;
template<typename... Args>
void add(Entity entity, Args&&... args);
void remove(Entity entity);
virtual bool tryRemove(Entity entity) override;
Entity getOwner(const T& component) const;
private:
std::vector<T> mComponents;
std::vector<Entity> mComponentToEntity;
std::unordered_map<Entity, Index> mEntityToComponent;
std::vector<std::bitset<ComponentCount>>& mEntityToBitset;
};
You can notice that it inherits from BaseComponentContainer which is defined by:
class BaseComponentContainer
{
public:
virtual ~BaseComponentContainer() = default;
virtual void reserve(std::size_t size) = 0;
virtual bool tryRemove(Entity entity) = 0;
};
The only purpose of this base class is to be able to store all the ComponentContainer instances in a container.
Now let us see the definition of the methods.
Firstly, the constructor, it takes a reference to the container which contains the bit sets of the entities. This class will use it to check if an entity has a component and to update the bit set of an entity when a component is added or removed:
ComponentContainer(std::vector<std::bitset<ComponentCount>>& entityToBitset) :
mEntityToBitset(entityToBitset)
{
}
The get method is simple, we just use mEntityToComponent to find the index of the entity component in mComponents:
T& get(Entity entity)
{
return mComponents[mEntityToComponent[entity]];
}
The add method uses its arguments to emplace a new component at the end of mComponents then it sets up the links to go from the entity to the component and from the component to the entity. Finally, it sets the bit corresponding to the component to true in the entity bitset:
template<typename... Args>
void add(Entity entity, Args&&... args)
{
auto index = static_cast<Index>(mComponents.size());
mComponents.emplace_back(std::forward<Args>(args)...);
mComponentToEntity.emplace_back(entity);
mEntityToComponent[entity] = index;
mEntityToBitset[entity][T::type] = true;
}
The remove method sets the bit corresponding to the component to false, then it moves the last component in mComponents to the index of the one we want to remove. It updates the links of the component we just moved and removes the one of the component we want to destroy:
void remove(Entity entity)
{
mEntityToBitset[entity][T::type] = false;
auto index = mEntityToComponent[entity];
// Update mComponents
mComponents[index] = std::move(mComponents.back());
mComponents.pop_back();
// Update mEntityToComponent
mEntityToComponent[mComponentToEntity.back()] = index;
mEntityToComponent.erase(entity);
// Update mComponentToEntity
mComponentToEntity[index] = mComponentToEntity.back();
mComponentToEntity.pop_back();
}
Moving the last component to the index of the one we want to destroy is what allows us to perform removal in constant time. Indeed, then we just have to remove the last component which can be done in constant time in a std::vector.
The tryRemove method tests if the entity has the component before trying to remove it:
virtual bool tryRemove(Entity entity) override
{
if (mEntityToBitset[entity][T::type])
{
remove(entity);
return true;
}
return false;
}
The getOwner method returns the entity that owns a component, it uses pointer arithmetic and mComponentToEntity to do so:
Entity getOwner(const T& component) const
{
auto begin = mComponents.data();
auto index = static_cast<std::size_t>(&component - begin);
return mComponentToEntity[index];
}
The last method is reserve which has the same purpose as EntityContainer one:
virtual void reserve(std::size_t size) override
{
mComponents.reserve(size);
mComponentToEntity.reserve(size);
mEntityToComponent.reserve(size);
}
System
Now let us take a look at the System class.
Each system has a bit set mRequirements which describes the components it requires. Then, it will maintain a set of entities that satisfy these requirements called mManagedEntities. Again to be able to implement all the operations in constant time, we will need a way to go from an entity to its index in mManagedEntities. To do so, we use an std::unordered_map called mEntityToManagedEntity.
Here is the declaration of System:
template<std::size_t ComponentCount, std::size_t SystemCount>
class System
{
public:
virtual ~System() = default;
protected:
template<typename ...Ts>
void setRequirements();
const std::vector<Entity>& getManagedEntities() const;
virtual void onManagedEntityAdded([[maybe_unused]] Entity entity);
virtual void onManagedEntityRemoved([[maybe_unused]] Entity entity);
private:
friend EntityManager<ComponentCount, SystemCount>;
std::bitset<ComponentCount> mRequirements;
std::size_t mType;
std::vector<Entity> mManagedEntities;
std::unordered_map<Entity, Index> mEntityToManagedEntity;
void setUp(std::size_t type);
void onEntityUpdated(Entity entity, const std::bitset<ComponentCount>& components);
void onEntityRemoved(Entity entity);
void addEntity(Entity entity);
void removeEntity(Entity entity);
};
setRequirements takes advantage of a fold expression to set the bits:
template<typename ...Ts>
void setRequirements()
{
(mRequirements.set(Ts::type), ...);
}
getManagedEntities is the getter that will be used by the derived classes to access to the managed entities:
const std::vector<Entity>& getManagedEntities() const
{
return mManagedEntities;
}
It returns a constant reference to ensure that the derived class won’t try to modify mManagedEntities.
onManagedEntityAdded and onManagedEntityRemoved are empty. They are aimed to be overrided. They will be called respectively when an entity is added to or removed from mManagedEntities.
The next methods are private and only accessible by EntityManager which is declared as a friend class.
setUp will be called by the entity manager to assign an id to the system. It may then use it to index arrays:
void setUp(std::size_t type)
{
mType = type;
}
onEntityUpdated is called when an entity is modified i.e. a component is added or removed. The system checks if the requirements are satisfied and if the entity is already managed. If it satisfies the requirements and does not already manage it, it will add it. However, if it does not satisfy the requirements and it was managed, it will remove it. In the other cases, the system does nothing:
void onEntityUpdated(Entity entity, const std::bitset<ComponentCount>& components)
{
auto satisfied = (mRequirements & components) == mRequirements;
auto managed = mEntityToManagedEntity.find(entity) != std::end(mEntityToManagedEntity);
if (satisfied && !managed)
addEntity(entity);
else if (!satisfied && managed)
removeEntity(entity);
}
onEntityRemoved is called by the entity manager when an entity is removed. If the entity was managed by the system, it removes it:
void onEntityRemoved(Entity entity)
{
if (mEntityToManagedEntity.find(entity) != std::end(mEntityToManagedEntity))
removeEntity(entity);
}
Finally addEntity and removeEntity are just utility methods.
addEntity sets up the link to go from the added entity to its index in mManagedEntities, it adds entity and finally calls onManagedEntityAdded:
void addEntity(Entity entity)
{
mEntityToManagedEntity[entity] = static_cast<Index>(mManagedEntities.size());
mManagedEntities.emplace_back(entity);
onManagedEntityAdded(entity);
}
removeEntity firstly calls onManagedEntityRemoved. Then it moves the last managed entity to the index of the one to remove. It updates the link of the moved entity. Finally it removes the entity to remove from mManagedEntities and mEntityToManagedEntity:
void removeEntity(Entity entity)
{
onManagedEntityRemoved(entity);
auto index = mEntityToManagedEntity[entity];
mEntityToManagedEntity[mManagedEntities.back()] = index;
mEntityToManagedEntity.erase(entity);
mManagedEntities[index] = mManagedEntities.back();
mManagedEntities.pop_back();
}
EntityManager
All the important logic is in the other classes, the entity manager just ties all the pieces together.
Let us look at its declaration:
template<std::size_t ComponentCount, std::size_t SystemCount>
class EntityManager
{
public:
template<typename T>
void registerComponent();
template<typename T, typename ...Args>
T* createSystem(Args&& ...args);
void reserve(std::size_t size);
Entity createEntity();
void removeEntity(Entity entity);
template<typename T>
bool hasComponent(Entity entity) const;
template<typename ...Ts>
bool hasComponents(Entity entity) const;
template<typename T>
T& getComponent(Entity entity);
template<typename T>
const T& getComponent(Entity entity) const;
template<typename ...Ts>
std::tuple<Ts&...> getComponents(Entity entity);
template<typename ...Ts>
std::tuple<const Ts&...> getComponents(Entity entity) const;
template<typename T, typename... Args>
void addComponent(Entity entity, Args&&... args);
template<typename T>
void removeComponent(Entity entity);
template<typename T>
Entity getOwner(const T& component) const;
private:
std::array<std::unique_ptr<BaseComponentContainer>, ComponentCount> mComponentContainers;
EntityContainer<ComponentCount, SystemCount> mEntities;
std::vector<std::unique_ptr<System<ComponentCount, SystemCount>>> mSystems;
template<typename T>
void checkComponentType() const;
template<typename ...Ts>
void checkComponentTypes() const;
template<typename T>
auto getComponentContainer();
template<typename T>
auto getComponentContainer() const;
};
The EntityManager class has three member variables: mComponentContainers which stores std::unique_ptrs to BaseComponentContainer, mEntities which is just an instance of EntityContainer and mSystems which stores unique_ptrs to System.
The class has a lot of methods but they all are really simple.
Let us first look at getComponentContainer which returns a pointer to the component container which manages the components of type T:
template<typename T>
auto getComponentContainer()
{
return static_cast<ComponentContainer<T, ComponentCount, SystemCount>*>(mComponentContainers[T::type].get());
}
The other utility function is checkComponentType which just checks that the component type id is below the maximum number of components:
template<typename T>
void checkComponentType() const
{
static_assert(T::type < ComponentCount);
}
checkComponentTypes just uses a fold expression to make the check for several types:
template<typename ...Ts>
void checkComponentTypes() const
{
(checkComponentType<Ts>(), ...);
}
registerComponent creates a new component container for the given type:
template<typename T>
void registerComponent()
{
checkComponentType<T>();
mComponentContainers[T::type] = std::make_unique<ComponentContainer<T, ComponentCount, SystemCount>>(
mEntities.getEntityToBitset());
}
createSystem creates a new system of the given type and sets its type:
template<typename T, typename ...Args>
T* createSystem(Args&& ...args)
{
auto type = mSystems.size();
auto& system = mSystems.emplace_back(std::make_unique<T>(std::forward<Args>(args)...));
system->setUp(type);
return static_cast<T*>(system.get());
}
The reserve method just calls the reserve methods of ComponentContainer and EntityContainer:
void reserve(std::size_t size)
{
for (auto i = std::size_t(0); i < ComponentCount; ++i)
{
if (mComponentContainers[i])
mComponentContainers[i]->reserve(size);
}
mEntities.reserve(size);
}
The createEntity method just returns the result of EntityManager create method:
Entity createEntity()
{
return mEntities.create();
}
hasComponent uses the bit set of an entity to quickly check if this entity has a component of the given type:
template<typename T>
bool hasComponent(Entity entity) const
{
checkComponentType<T>();
return mEntities.getBitset(entity)[T::type];
}
hasComponents uses a fold expression to create a bit set that represents the required components and then uses it against the entity bit set to assess if the entity has all the required components:
template<typename ...Ts>
bool hasComponents(Entity entity) const
{
checkComponentTypes<Ts...>();
auto requirements = std::bitset<ComponentCount>();
(requirements.set(Ts::type), ...);
return (requirements & mEntities.getBitset(entity)) == requirements;
}
getComponent just forwards the request to the right component container:
template<typename T>
T& getComponent(Entity entity)
{
checkComponentType<T>();
return getComponentContainer<T>()->get(entity);
}
getComponents returns a tuple of references to the requested components. It uses std::tie and a fold expression again to achieve that:
template<typename ...Ts>
std::tuple<Ts&...> getComponents(Entity entity)
{
checkComponentTypes<Ts...>();
return std::tie(getComponentContainer<Ts>()->get(entity)...);
}
addComponent and removeComponent forward the request to the right component container and then call systems’ onEntityUpdated:
template<typename T, typename... Args>
void addComponent(Entity entity, Args&&... args)
{
checkComponentType<T>();
getComponentContainer<T>()->add(entity, std::forward<Args>(args)...);
// Send message to systems
const auto& bitset = mEntities.getBitset(entity);
for (auto& system : mSystems)
system->onEntityUpdated(entity, bitset);
}
template<typename T>
void removeComponent(Entity entity)
{
checkComponentType<T>();
getComponentContainer<T>()->remove(entity);
// Send message to systems
const auto& bitset = mEntities.getBitset(entity);
for (auto& system : mSystems)
system->onEntityUpdated(entity, bitset);
}
Finally, getOwner forwards the request to the right component container:
template<typename T>
Entity getOwner(const T& component) const
{
checkComponentType<T>();
return getComponentContainer<T>()->getOwner(component);
}
That’s all for this first implementation. It only has 357 lines of code. You can find all the code in this branch.
Profiling and Benchmarks
Benchmarks
Now it is time to run the benchmarks on this first implementation!
Here are the results:
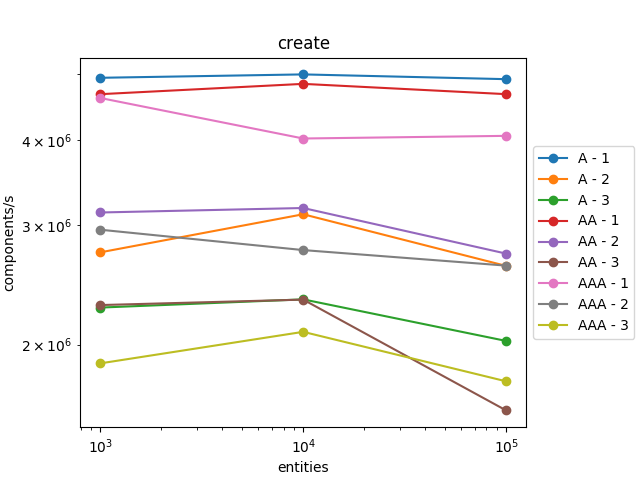
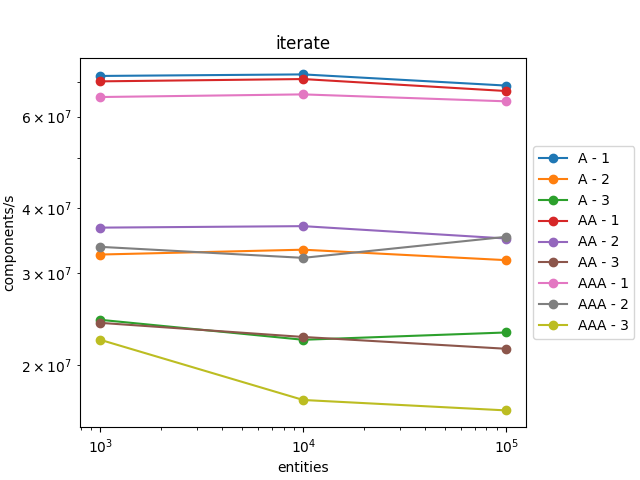
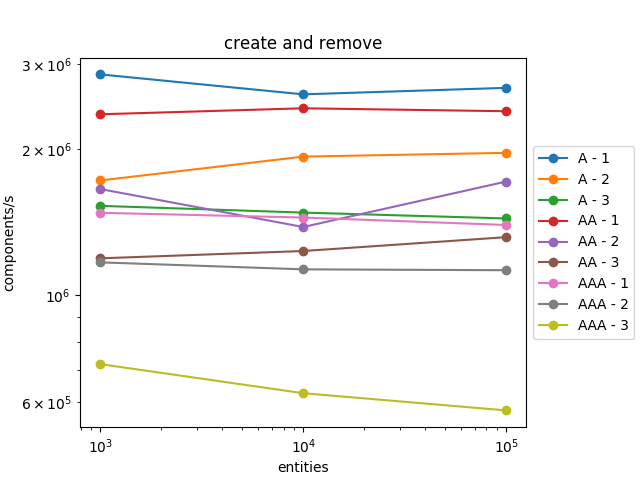
It scales pretty well! The number of components processed by second is roughly the same when the number of entities increases and for the different profiles (A, AA, and AAA).
It also scales well with the number of components in the entities. When we iterate over entities with three components, it is three times slower than iterating over entities with one component which is expected as we must retrieve the three components.
Cache Misses
I run the example available here with cachegrind to measure the number of cache misses.
Here is the result with 10000 entities:
==1652== D refs: 277,577,353 (254,775,159 rd + 22,802,194 wr)
==1652== D1 misses: 20,814,368 ( 20,759,914 rd + 54,454 wr)
==1652== LLd misses: 43,483 ( 7,847 rd + 35,636 wr)
==1652== D1 miss rate: 7.5% ( 8.1% + 0.2% )
==1652== LLd miss rate: 0.0% ( 0.0% + 0.2% )
Here is the result with 100000 entities:
==1738== D refs: 2,762,879,670 (2,539,368,564 rd + 223,511,106 wr)
==1738== D1 misses: 207,415,181 ( 206,902,072 rd + 513,109 wr)
==1738== LLd misses: 207,274,328 ( 206,789,289 rd + 485,039 wr)
==1738== D1 miss rate: 7.5% ( 8.1% + 0.2% )
==1738== LLd miss rate: 7.5% ( 8.1% + 0.2% )
The results are relatively good. That is just a bit weird that they are so much LLd misses with 100000 entities.
Profiling
To have an idea of which parts of the current implementation are taking time, I profiled the example with gprof.
Here is the result:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
57.45 1.16 1.16 200300000 0.00 0.00 std::__detail::_Map_base<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true>, true>::operator[](unsigned int const&)
19.31 1.55 0.39 main
16.34 1.88 0.33 200500000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::_M_find_before_node(unsigned long, unsigned int const&, unsigned long) const
3.96 1.96 0.08 300000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::_M_insert_unique_node(unsigned long, unsigned long, std::__detail::_Hash_node<std::pair<unsigned int const, unsigned int>, false>*)
2.48 2.01 0.05 300000 0.00 0.00 unsigned int& std::vector<unsigned int, std::allocator<unsigned int> >::emplace_back<unsigned int&>(unsigned int&)
0.50 2.02 0.01 3 3.33 3.33 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::~_Hashtable()
0.00 2.02 0.00 200000 0.00 0.00 std::_Hashtable<unsigned int, std::pair<unsigned int const, unsigned int>, std::allocator<std::pair<unsigned int const, unsigned int> >, std::__detail::_Select1st, std::equal_to<unsigned int>, std::hash<unsigned int>, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<false, false, true> >::find(unsigned int const&)
The results may be a bit biased as I compiled with -O1 flag so that gprof outputs something sensible. With a higher level of optimization, the compiler seems to aggressively inline everything and gprof reports almost nothing.
According to gprof, it seems that the std::unordered_maps are clearly the bottleneck of this implementation. If we want to optimize it, we may want to get rid of them.
Comparison with std::map
I was curious to see the difference of performance between std::unordered_map and std::map so I replaced std::unordered_maps by std::maps in the code. This implementation is available here
Here are the results on the benchmarks:
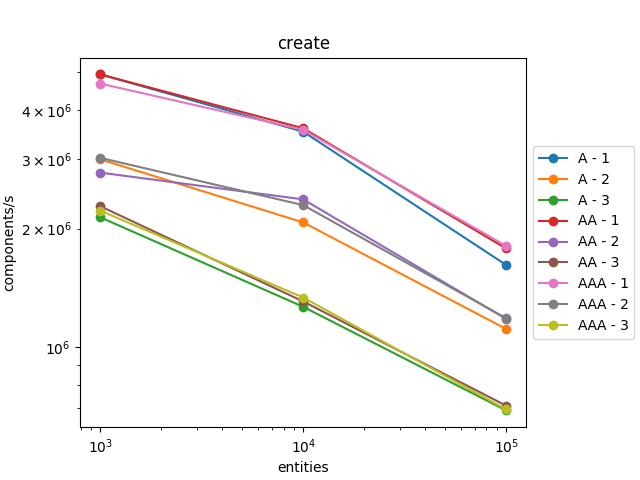
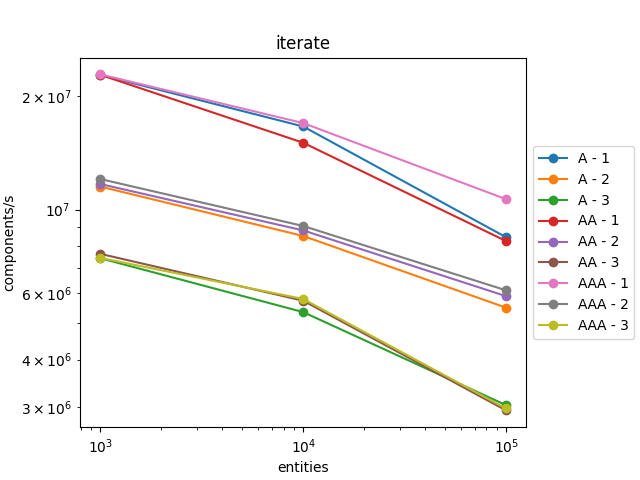
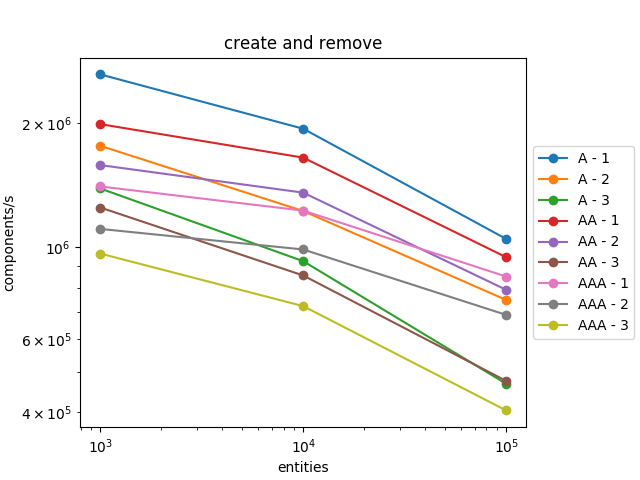
We can observe that this time, it scales badly with the number of entities. And even with 1000 entities, it is twice slower on iteration than the version with std::unordered_maps.
Conclusion
It is the end of the first part of this series. We have built a simple but already useful entity-component-system library. We will use it as a baseline for later improvements and optimizations.
In the next part, we will show how to improve the performance by replacing the std::unordered_maps by std::vectors. In addition, we will show how to automatically assign a type id to components.
See you there!
If you are interested in my adventures during the development of Vagabond, you can follow me on Twitter.
