pvigier's blog
computer science, programming and other ideas
Entity-Component-System – Part 2
In this article, we will take back our entity-component-system implementation where we left it in the previous article and try to improve it.
Replacing std::unordered_maps by std::vectors
As we saw in the last article, std::unordered_maps were the bottleneck of our implementation. Thus, instead of using std::unordered_maps for mEntityToComponent in ComponentContainer and mEntityToManagedEntity in System, we will use std::vectors.
Changes
The changes are really simple, you can review them here.
The only subtlety is that we have to ensure that the vectors mEntityToComponent and mEntityToManagedEntity are long enough to be indexed by any entity. To be able to do that easily, I chose to store those vectors in EntityContainer where we know the maximum entity id. Then I pass the vectors to component containers and systems by reference or pointer in the entity manager.
You can find the code after the changes in this branch.
Results
Let us see if this version performs better than the previous one:
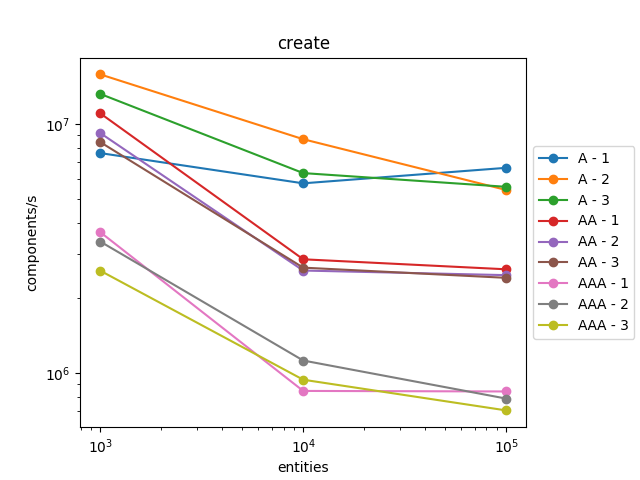
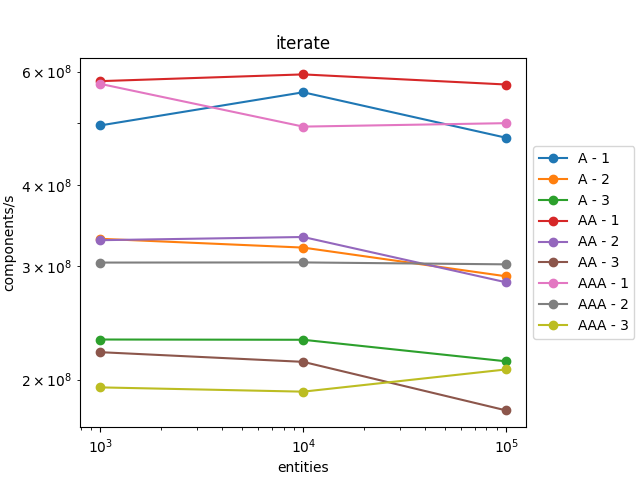
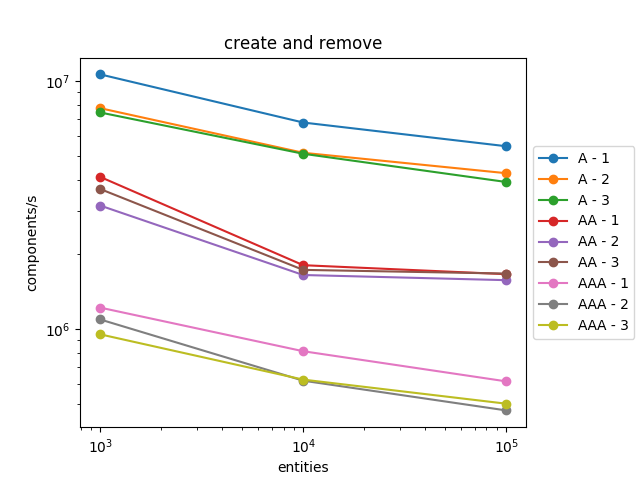
We can see that creation and removal is a bit slower when there are lots of components and systems.
However, iteration is a lot faster, nearly ten times faster! And it scales very well. This speedup largely counterbalances the slowdown in creation and removal. Indeed, an entity will be iterated a large number of times while it is created and removed only once.
Now let us see, if it also reduces the number of cache misses.
Here is the output of cachegrind with 10000 entities:
==1374== D refs: 94,563,949 (72,082,880 rd + 22,481,069 wr)
==1374== D1 misses: 4,813,780 ( 4,417,702 rd + 396,078 wr)
==1374== LLd misses: 378,905 ( 9,626 rd + 369,279 wr)
==1374== D1 miss rate: 5.1% ( 6.1% + 1.8% )
==1374== LLd miss rate: 0.4% ( 0.0% + 1.6% )
And the output with 100000 entities:
==1307== D refs: 938,405,796 (715,424,940 rd + 222,980,856 wr)
==1307== D1 misses: 51,034,738 ( 44,045,090 rd + 6,989,648 wr)
==1307== LLd misses: 5,866,508 ( 1,997,948 rd + 3,868,560 wr)
==1307== D1 miss rate: 5.4% ( 6.2% + 3.1% )
==1307== LLd miss rate: 0.6% ( 0.3% + 1.7% )
We can observe that this version does approximately three times less references and four times less cache misses.
Automatic Types
The last improvement I will present is the automatic generation of type ids for the components.
Changes
You can review all the changes to achieve automatic generation of type ids here.
The idea to be able to assign one different id to each component type is to take advantage of CRTP and a function with a static counter:
template<typename T>
class Component
{
public:
static const std::size_t type;
};
std::size_t generateComponentType()
{
static auto counter = std::size_t(0);
return counter++;
}
template<typename T>
const std::size_t Component<T>::type = generateComponentType();
We can notice that the type id is now generated at run time while before it was known at compile time.
You can find the code after the changes in this branch.
Results
I ran the benchmarks on this version to check the performance:
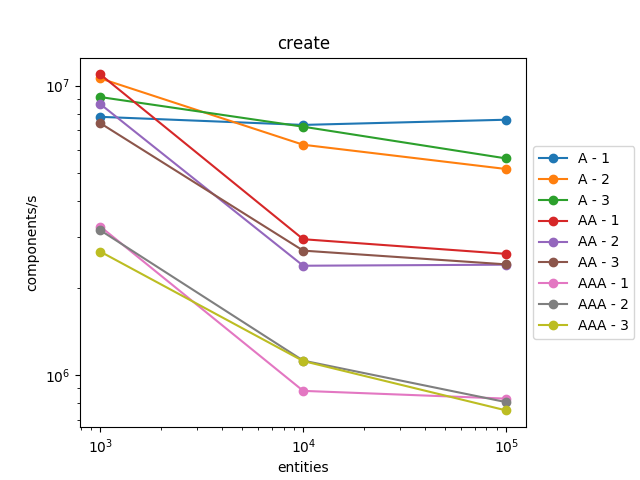
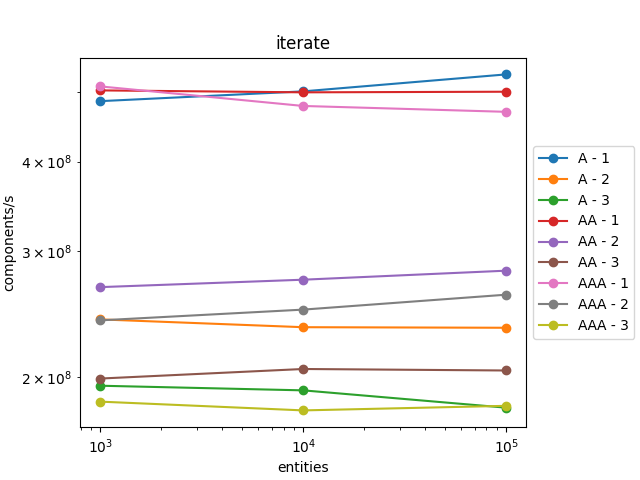
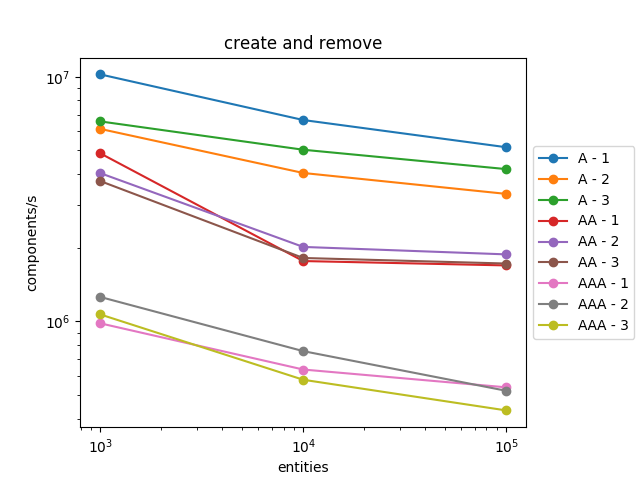
The results are roughly the same for creation and removal. However, we can notice that iteration is a bit slower, roughly 10% slower.
We can explain this slowdown by the fact that previously the compiler known the type ids at compile time and consequently was able to better optimize the code.
It is a bit cumbersome and error-prone to have to specify the type ids of components manually. Thus, even if we lose a bit of performance it is still an improvement in the usability of our entity-component-system library.
Ideas for Improvements
Before finishing this article, I would like to share with you some ideas for improvements. I have not implemented them yet but I may do it in the future.
Dynamic Number of Components and Systems
It is not convenient to have to specify in advance the maximum number of components and systems as template parameters. I think it would be possible to replace the std::arrays in EntityManager by std::vectors without a big penalty in performance.
However, std::bitset requires to know its number of bits at compile time. Currently, my idea to fix this issue is that instead of having a std::vector<bitset<ComponentCount>> in EntityContainer, we just use a std::vector<char> and we allocate enough bytes to represent the bit sets of all the entities. Then, we implement a lightweight class BitsetView that takes as input a pair of pointers for the beginning and the end of the bit set and we perform all the useful operations of std::bitset in this range of memory.
Another idea is to not use bit sets anymore and just rely on mEntityToComponent to determine if an entity has a component or not.
Easier Iteration of Components
For now, if a system wants to iterate the components of its managed entities, we have to do as follow:
for (const auto& entity : getManagedEntities())
{
auto [position, velocity] = mEntityManager.getComponents<Position, Velocity>(entity);
...
}
It would be nicer and simpler, if we can do something like that:
for (auto& [position, velocity] : mEntityManager.getComponents<Position, Velocity>(mManagedEntities))
{
...
}
This will be a piece of cake with C++20 std::view::transform from the ranges library.
Unfortunately, this is not ready yet. I could have used Eric Niebler’s range library but I do not want to add a dependency.
The solution would be implement a class EntityRangeView that would take as template parameters the component types to retrieve and as constructor parameter a reference to a std::vector of entities. Then, we just have to implement begin, end and an iterator type to be able to obtain the desired behavior. It is not really difficult but a bit cumbersome to write.
Optimization of Event Dispatching
Currently, when we add or remove a component to an entity, we call the onEntityUpdated of all systems. It is a bit inefficient as many systems are not interested by the component type that just has been modified.
To mitigate that, we can store pointers to systems interested by a given component type in a data structure like std::array<std::vector<System<ComponentCount, SystemCount>>, ComponentCount>. Then, when we add or remove a component, we just call the method onEntityUpdated of the systems that are interested by this component.
Subsets of Entities Managed by the Entity Manager Instead of Systems
My last idea induces more changes in the design of the library.
Instead that it is systems that manage their sets of entities, it would be the role of the entity manager. The advantage would be that if two systems are interested in the same set of components, we do not duplicate the subset of entities that satisfy these requirements.
The systems would just declare their requirements to the entity manager. Then the entity manager will maintain all the different subsets of entities. Finally, the systems would request entities with a syntax like this one:
for (const auto& entity : mEntityManager.getEntitiesWith<Position, Velocity>())
{
...
}
Conclusion
It is the end, for now, of this series of article on my entity-component-system implementation. I may write new articles if I make some improvements in the future.
The implementation described here while simple: it has less than 500 lines of code, it also has good performance. All operations are implemented in (amortized) constant time. Moreover, in practice, it is cache-friendly and is very fast to retrieve and iterate entities.
I hope you find these articles interesting or even useful for you.
See you next week for more!
To Go Further
Here are some useful resources to dive deeper in entity-component-systems:
- Michele Caini, the creator of entt, is writing a very interesting series of articles on entity-component-system called ECS back and forth.
- The Entity Systems Wiki also contains very useful information and links.
If you are interested in my adventures during the development of Vagabond, you can follow me on Twitter.
